Полезные статьи
Подписка на рассылкуКритичная ошибка Я.Вебмастер: "Найдены страницы-дубли с GET-параметрами" — как её решить?
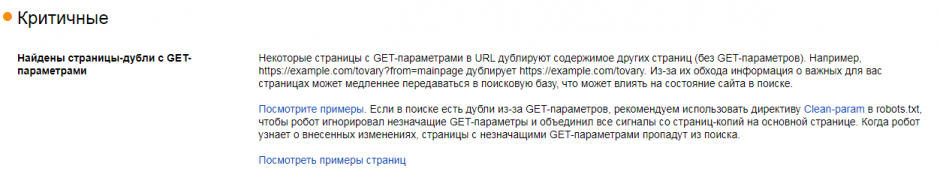
С лета 2021 года Яндекс.Вебмастер стал информировать вебмастеров о наличии на сайтах страниц-дублей с GET-параметрами, причем помечается эта проблема как критичная. В этой статье мы расскажем, что это за проблема и как её решить проще всего.
Содержание:
- Что такое страницы дубли с GET-параметрами
- Четыре основных способа убрать дубли страниц из индекса
- Самый эффективный способ избавления от страниц-дублей с GET-параметрами
1. Что такое страницы дубли с GET-параметрами
Для начала определимся с тем, что такое "GET-параметр" – это динамический параметр в URL страниц, с помощью которого можно динамически менять контент документа. Их можно заметить, в URL-адресе находятся после символа «?» и разделяются между собой знаком «&». Эти параметры могут генерироваться как изнутри, системой управления сайтом, например, различные страницы пагинации или сортировки (?page=2 или ?sort=abc), так и извне, например, мы самостоятельно можем добавить UTM-метки для отслеживания трафика или любые другие рандомные параметры.
Страницы с GET-параметрами считаются поисковыми системами как полноценные самостоятельные документы и при наличии схожего контента часто определяются как дубли, например, site.ru и site.ru?utm_source=test, будут признаны дублями.
2. Четыре основных способа убрать дубли страниц из индекса
2.1. Clean-param
Clean-param – специальная директива для файла robots.txt, в которой вы перечисляете все параметры, нуждающиеся в закрытии, то есть, если поисковый робот Яндекса будет видеть такой URL, то не будет посещать данную страницу.
Как использовать: перечислите в файле robots.txt, в одной или нескольких директивах Clean-param, все параметры, которые встречаются в URL вашего сайта, через амперсанд (значок «&»), например, «Clean-param: page&sort», чтобы закрыть URL вроде site.ru?page=2 и site.ru?sort=abc.
Преимущества:
- Передает показатели страницы на основную.
Недостатки:
- Учитывается только поисковой системой Яндекс.
- Придется постоянно отслеживать появление новых параметров и добавлять их.
- Длина директивы ограничена 500 знаками.
2.2. Disallow
Disallow – директива для файла robots.txt, которая полностью закрывает от индексации URL, имеющие GET-параметры.
Как использовать: просто добавьте в файл robots.txt директиву «Disallow: *?*».
Преимущества:
- Быстро и просто.
- Учитывается всеми поисковыми системами.
Недостатки:
- Роботы совсем не посещают страницы с Get-параметрами, а значит и не имеют возможности просматривать их содержимое, а оно может отличаться, как например, на страницах пагинации могут содержаться разные товары.
- Не передает показатели страницы на основную.
2.3. Атрибут rel="canonical"
Canonical – атрибут тега link, позволяющий указывать каноническую страницу, тем самым сообщать, какой URL является основным, а какой дублем.
Как использовать: на страницах с GET-параметром, в блоке <head> разместите тег link с указанием канонической страницы, без параметра, например, на странице site.ru?page=2 нужно указать тег <link rel="canonical" href=" site.ru?page=2">.
Преимущества:
- Передает показатели страницы на основную.
- Учитывается всеми поисковыми системами.
Недостатки:
- Не строгое правило, поэтому часть страниц все равно попадают в индекс поисковых систем.
- Необходимо привлечение разработчиков для реализации на всех нужных страницах по условиям.
2.4. Метатег robots
Noindex – атрибут метатега robots, закрывающий конкретные страницы от индексации, при этом, позволяющий поисковым роботам заходить на такие страницы и видеть контент.
Как использовать: на страницах с GET-параметром, в блоке <head> разместите мета-тег robots, например, на странице site.ru?page=2 нужно указать мета-тег <meta name="robots" content="noindex" />.
Преимущества:
- Строгое правило для роботов поисковых систем, позволяющее удалить все страницы из поисковой выдачи.
- Учитывается всеми поисковыми системами.
Недостатки:
- Не передает показатели страницы на основную.
- Необходимо привлечение разработчиков для реализации на всех нужных страницах по условиям.
3. Самый эффективный способ избавления от страниц-дублей с GET-параметрами
Идеальным решением будет использование сочетания двух методов noindex и сanonical, которые будут компенсировать недостатки друг друга.
Атрибут rel="canonical" будет передавать все параметры со страницы с GET-параметрами на основную, при этом, noindex метатега robots будет более строгим правилом, что позволит сократить количество дублей страниц до минимума. Кроме того, оба этих способа работают для всех поисковых систем, а не только для Яндекс.
Далее мы рассмотрим несколько готовых решений для популярных CMS, которые позволять идеально реализовать удаление страниц-дублей с GET-параметрами из индекса поисковых систем:
3.1. Webasyst / Shop-Script
Для данной CMS разработаны два плагина:
- "Meta Robots Tag" — проставляет метатег robots.
- "Link canonical" — проставляет атрибут rel="canonical".
Плагины добавляют на страницы нужные теги, причем делают как для страниц с GET-параметрами, так и для различных других технических страниц. Их можно гибко настраивать под свои нужды.
3.2. 1С-Битрикс
Проставление атрибута rel="canonical" можно настроить с помощью готового решения:
А для простановки тега robots нет готового решения, но можно разместить код в шаблоне темы дизайна.
Теперь вы знаете как избавиться от дублей в Яндекс.Вебмастере и удалить лишние страницы с GET-параметрами из индекса поисковых систем эффективнее всего.